
Facebook depends on server fleets spread across global data centers to run applications and ensure optimal service performance. Ensuring the reliability of our server hardware is crucial to managing failures efficiently and minimizing service disruptions on a large scale.
Hardware components can fail due to various reasons, like material degradation (such as mechanical parts in hard disk drives), exceeding device endurance levels (like NAND flash devices), environmental factors (such as humidity-induced corrosion), and manufacturing flaws.
Anticipating some hardware failures in our data centers, we’ve implemented systems like our cluster management system to minimize service disruptions. In this article, we introduce four key methodologies enhancing hardware availability. We’ve developed systems capable of detecting and resolving issues, monitoring and remedying hardware events without impacting application performance, employing proactive approaches for repairs, predictive methods for remediation, and automating root cause analysis for hardware and system failures at scale to swiftly resolve issues.
How we handle hardware remediation
At regular intervals, we utilize MachineChecker on individual servers to identify hardware and connectivity issues. Once alerts are generated in a centralized system, Facebook Auto-Remediation (FBAR) takes charge, implementing tailored solutions to resolve the detected errors. To ensure sufficient capacity for Facebook’s services, we can apply rate limits, controlling the number of servers undergoing repairs simultaneously.
Should FBAR be unable to restore a server to its healthy state, the issue is transferred to Cyborg. Cyborg can execute more intricate solutions like firmware or kernel upgrades, and system reimaging. Cases requiring manual intervention by a technician prompt the system to generate a ticket in our repair ticketing system.

How we minimize the negative impact of error reporting on server performance
MachineChecker identifies hardware failures by scanning server logs for error reports. When a hardware error occurs, the system detects it (e.g., through a parity check failure), sending an interrupt signal to the CPU for error handling and logging.
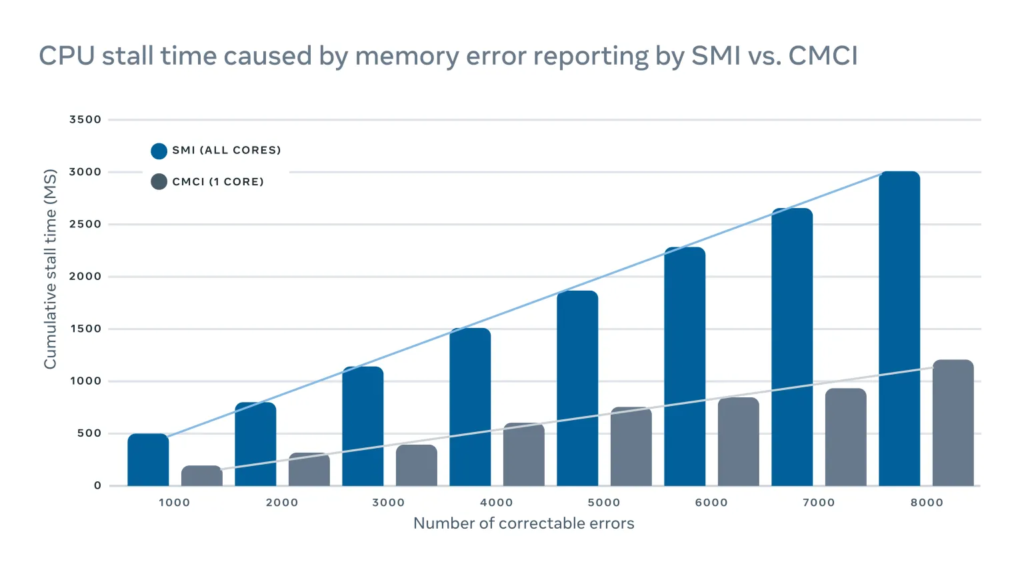
These interrupt signals are high-priority, causing the CPU to pause its regular operations and focus on addressing the error. However, this pause negatively impacts server performance. For instance, logging correctable memory errors using a traditional system management interrupt (SMI) would halt all CPU cores, whereas a correctable machine check interrupt (CMCI) would only pause one CPU core, allowing the others to continue normal operation.
Although these CPU stalls are brief, lasting only a few hundred milliseconds, they can disrupt latency-sensitive services. At scale, interruptions on a few machines can cascade, significantly impacting overall service performance.
To mitigate the performance impact from error reporting, we’ve adopted a hybrid memory error reporting mechanism. This method utilizes both CMCI and SMI, maintaining accuracy in identifying correctable memory errors while reducing the performance impact.
How we leverage machine learning to predict repairs
Given our frequent introduction of new hardware and software configurations in data centers, adapting our auto-remediation system’s rules becomes essential.
When the automated system fails to resolve a hardware issue, it results in a ticket for manual repair. The influx of new hardware and software introduces fresh potential failure scenarios requiring attention. However, a lag may exist between implementing new elements and integrating corresponding remediation rules. This gap may lead to some repair tickets being labeled as “undiagnosed,” where no repair action is suggested, or “misdiagnosed,” where the suggested action proves ineffective. Consequently, this can increase labor and system downtime as technicians must manually diagnose issues.
To bridge this gap, we’ve developed a machine learning framework. It learns from past solutions to predict necessary repairs for current undiagnosed and misdiagnosed repair tickets. Factoring in the cost-benefit of correct and incorrect predictions, we set a confidence threshold for each repair action and optimize their sequence. For instance, the algorithm may prioritize actions like reboots or firmware upgrades, which require no physical hardware repair and consume less time. In essence, machine learning not only predicts how to fix undiagnosed or misdiagnosed issues but also prioritizes the most critical ones, enhancing efficiency.

How we’ve automated fleet-level root cause analysis
Besides the server logs that document reboots, kernel panics, and out-of-memory incidents, our production system also encompasses software and tooling logs. However, the sheer volume and intricacy of these logs make it challenging to collectively examine them for correlations.
To address this, we’ve introduced a scalable root-cause-analysis (RCA) tool capable of sifting through millions of log entries, each potentially characterized by numerous columns. This tool aims to uncover comprehensible and actionable correlations.
By leveraging data pre-aggregation via Scuba, a real-time in-memory database, we’ve notably enhanced the scalability of a traditional pattern mining algorithm, FP-Growth. This empowers our RCA framework to uncover correlations efficiently. Moreover, we’ve incorporated a series of filters to refine reported correlations, improving result interpretability. This analyzer has been extensively deployed across Facebook for conducting RCA concerning hardware component failure rates, unexpected server reboots, and software failures.
